
Ziyi Wu1,2,
Nikita Dvornik3,1,
Klaus Greff4,
Thomas Kipf4,*,
Animesh Garg1,2,*
1University of Toronto
2Vector Institute
3Samsung AI Centre Toronto
4Google Research
* Equal supervision
Understanding dynamics from visual observations is a challenging problem that requires disentangling individual objects from the scene and learning their interactions. While recent object-centric models can successfully decompose a scene into objects, modeling their dynamics effectively still remains a challenge. We address this problem by introducing SlotFormer -- a Transformer-based autoregressive model operating on learned object-centric representations. Given a video clip, our approach reasons over object features to model spatio-temporal relationships and predicts accurate future object states. In this paper, , we successfully apply SlotFormer to perform video prediction on datasets with complex object interactions. Moreover, the unsupervised SlotFormer's dynamics model can be used to improve the performance on supervised downstream tasks, such as Visual Question Answering (VQA), and goal-conditioned planning. Compared to past works on dynamics modeling, our method achieves significantly better long-term synthesis of object dynamics, while retaining high quality visual generation. Besides, SlotFormer enables VQA models to reason about the future without object-level labels, even outperforming counterparts that use ground-truth annotations. Finally, we show its ability to serve as a world model for model-based planning, which is competitive with methods designed specifically for such tasks.
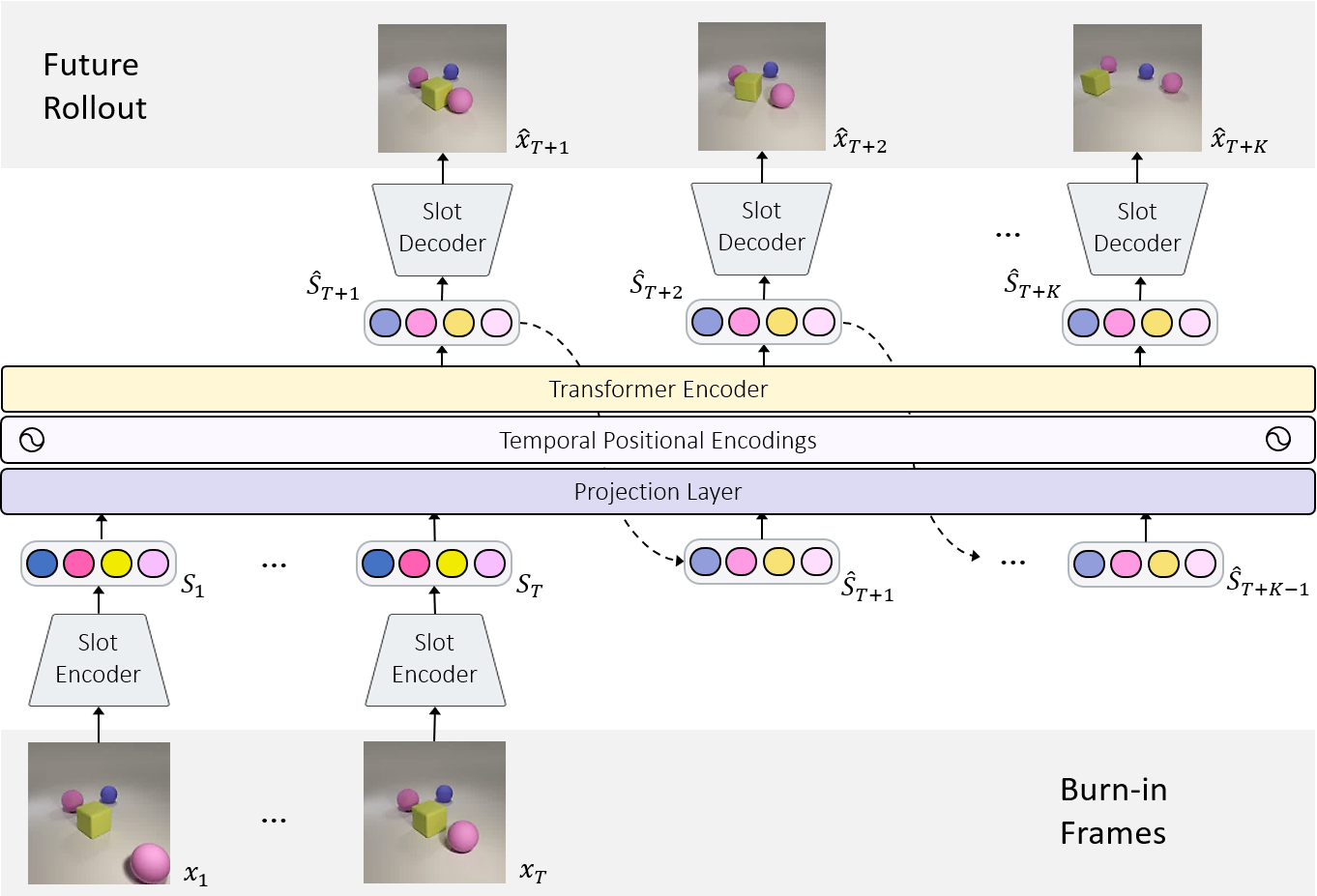
SlotFormer architecture overview. Taking multiple video frames $\{x_t\}_{t=1}^T$ as input, we first extract object slots $\{\mathcal{S}_t\}_{t=1}^T$ using the pretrained object-centric model. Then, slots are linearly projected and added with temporal positional encoding. The resulting tokens are fed to the Transformer module to generate future slots $\{\hat{\mathcal{S}}_{T+k}\}_{k=1}^K$ in an autoregressive manner.
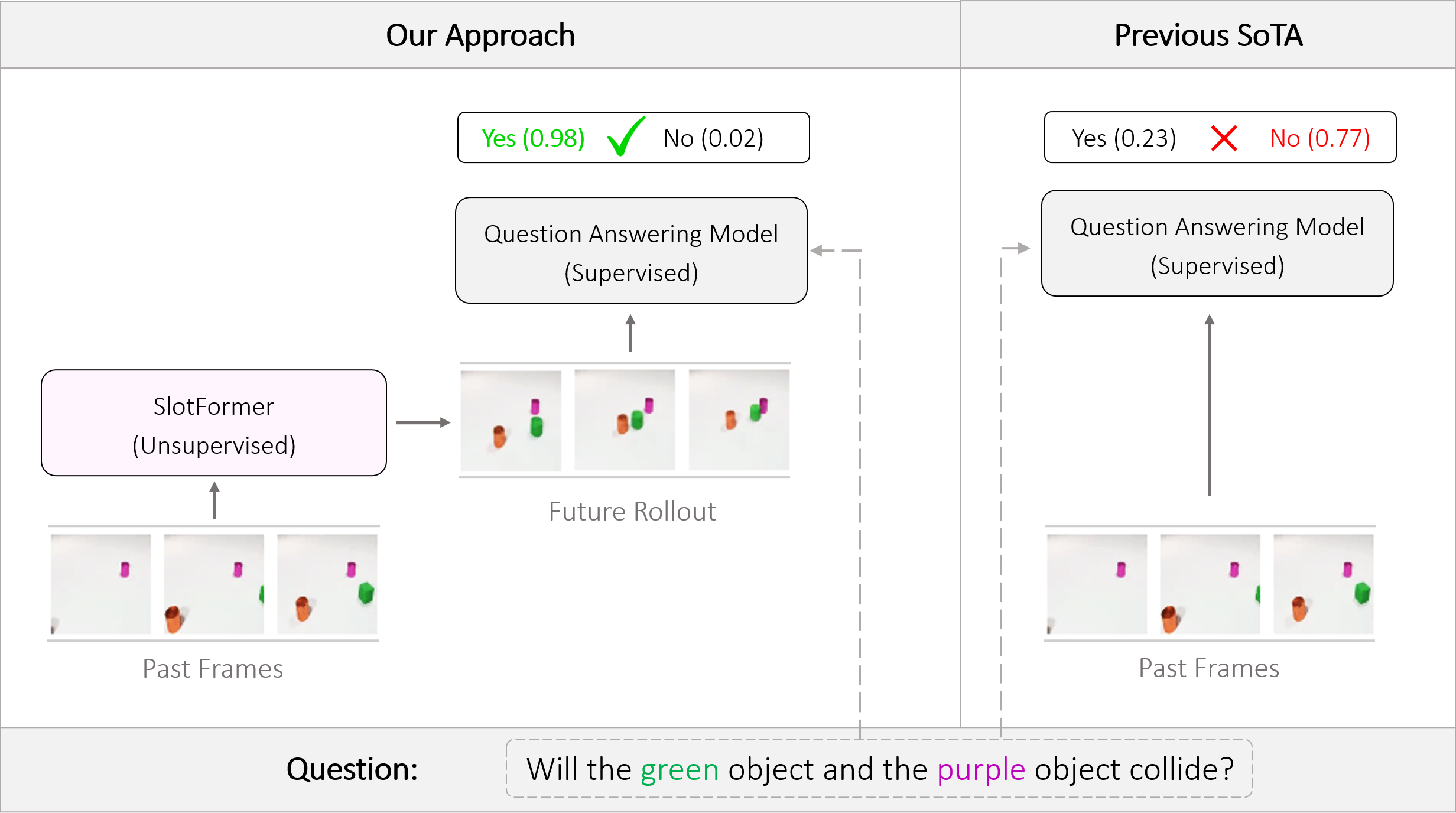
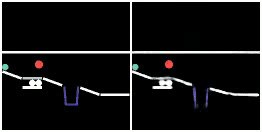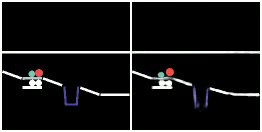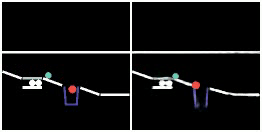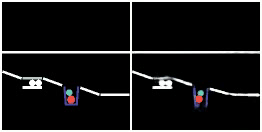
SlotFormer integrated with downstream task models. Given a video and a question about the future event, (left) a vanilla VQA model only reasons over observed frames and predicts the wrong answer. (right) In contrast, we leverage SlotFormer to simulate accurate future frames, which contain useful information for producing the correct answer. In this way, the unsupervised dynamics knowledge learned by SlotFormer can be transfered to improve downstream supervised tasks.
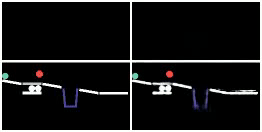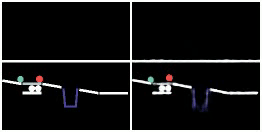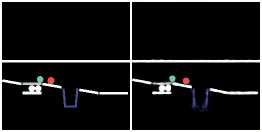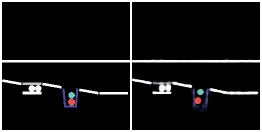
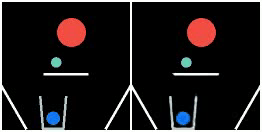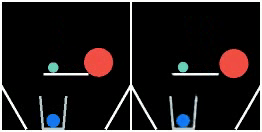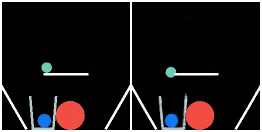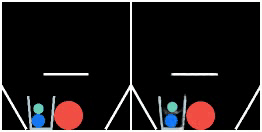
We show prediction results of SlotFormer and baselines on OBJ3D. We use 6 burn-in frames, and rollout until 50 frames.
| GT | PredRNN | SAVi-dyn | G-SWM | VQFormer | Ours |
|---|



We show prediction results of SlotFormer and baselines on CLEVRER. We use 6 burn-in frames, and rollout until 48 frames.
| GT | PredRNN | SAVi-dyn | G-SWM | VQFormer | Ours |
|---|



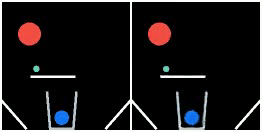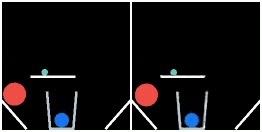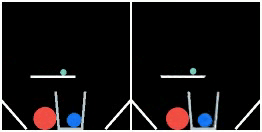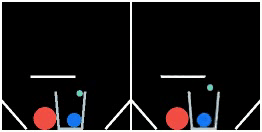
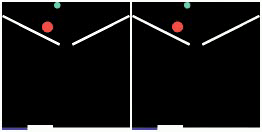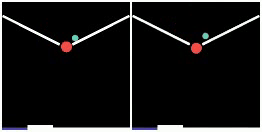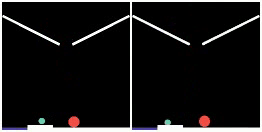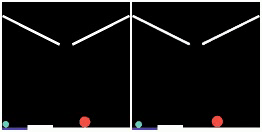
We show prediction results of SlotFormer on PHYRE. All of the rollouts are generated by observing only the first frame. We pause the first frame for 0.5s to show the initial configuration more clearly.
| GT | Ours | GT | Ours | GT | Ours |
|---|

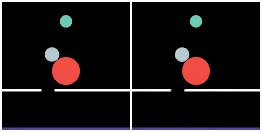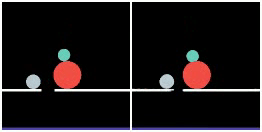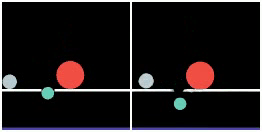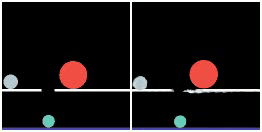










We show prediction results of SlotFormer on Physion. As discussed in the paper, Physion dataset features diverse physical phenomenon, and complicated visual appearance such textured objects, distractors, and diverse backgrounds. We adopt STEVE as the object-centric model, which can handle visually more complex data than SAVi.
However, STEVE uses a Transformer-based slot decoder to reconstruct the patch tokens produced by a trained dVAE encoder. So even its reconstructed images are of low quality (see Recon. column). In addition, we do not train SlotFormer using pixel reconstruction loss on Physion dataset due to GPU memory constraint. Therefore, the generated videos are visually unpleasant (See Rollout column). Nevertheless, they still preserve the correct motion of objects, such as object collisions and falling to the ground.
| GT | Recon. | Rollout | GT | Recon. | Rollout |








You may wonder whether STEVE really learns meaningful scene decomposition. Here we show the segmentation masks produced by STEVE, which highlights reasonable object segmentation. Empirically, we observe that image reconstruction loss helps with visual quality (e.g., color, shape), but has little effect on object dynamics. Therefore, using purely a slot reconstruction loss in the latent space is enough to learn the dynamics.
| Video | Per-Slot Masks |

[1] Lin, Zhixuan, et al. "Improving generative imagination in
object-centric world models." ICML. 2020.
[2] Wang, Yunbo, et al. "Predrnn: Recurrent neural networks for
predictive learning using spatiotemporal lstms." NeurIPS. 2017.
[3] Zoran, Daniel, et al. "PARTS: Unsupervised segmentation with
slots, attention and independence maximization." ICCV. 2021.
[4] Yi, Kexin, et al. "CLEVRER: CoLlision Events for Video
REpresentation and Reasoning." ICLR. 2020.
[5] Bakhtin, Anton, et al. "Phyre: A new benchmark for physical
reasoning." NeurIPS. 2019.
[6] Bear, Daniel, et al. "Physion: Evaluating Physical
Prediction from Vision in Humans and Machines." NeurIPS Datasets
and Benchmarks Track. 2021.
[7] Kipf, Thomas, et al. "Conditional Object-Centric Learning
from Video." ICLR. 2021.
[8] Singh, Gautam, Yi-Fu Wu, and Sungjin Ahn. "Simple
Unsupervised Object-Centric Learning for Complex and
Naturalistic Videos." NeurIPS. 2022.